Author:
- Markus Steindl and Sandra Wartner
RISC Software GmbH, Austria
Introduction:
No two languages are alike – while humans have created their own communication channels over thousands of years, millions of zeros and ones serve as machine code or machine language to enable computers to execute commands. Natural language processing (NLP, for short), enables machines to read, decode and process human language. Speech assistants, spelling correctors, email spam filters – NLP as a technology is omnipresent and already hides behind many processes and software applications deeply embedded in our everyday lives.
The flood of data generated by us humans is growing from day to day. For the year 2020 alone, growth statistics show that 1.7MB of data will be generated per person every second. We send photos, store documents in the cloud, stream music or videos, communicate via video conferencing tools, and use many more conveniences that the Internet offers us. In the last two years alone, approximately 90% of the world’s data was generated – and the numbers continue to rise. The COVID pandemic, among other things, is also contributing to a sharp increase in the growth rate due to the increased need for online communication and home offices.
A considerably large part of the created data consists of text data. We generate this data primarily ourselves, for example, by writing e-mails, product reviews, tweets, or text messages. At the same time, we can use the potential of the continuously growing tons of data to create the applications that increasingly support us in our everyday lives in the first place. We use translation functions from one language to another (e.g. DeepL), programs
alert us to typos when composing texts and messages, digital voice assistants such as Alexa, Cortana, Siri and co. support us in a wide range of activities, and search engines offer search completion. All these services and functions are built on one essential technology: Natural Language Processing (NLP).
Artificial intelligence makes humans and machines work better together
Machine processing of natural language does not represent a new field of research. However, due to the availability of higher computing power, enormous amounts of data (Big Data) as well as modern algorithms, the last years have brought a variety of revolutionary achievements in the NLP environment. As an interdisciplinary field of linguistics, computer science, and artificial intelligence (AI), NLP enables communication between humans and
machines in different forms (written and spoken) and in a variety of languages.
If we want to ask the Google Assistant on our smartphone to have a synthesized voice explain NLP to us, a simple “OK Google” and the trailing question will suffice. In the best case, we will receive an answer that satisfies us and provides exactly the information we were looking for. While this task sounds relatively simple for execution by a human, for a machine it means breaking down language into its elementary components, understanding the question and context, and having to solve sequentially different problems. Figure 1 provides an overview of the components of NLP.
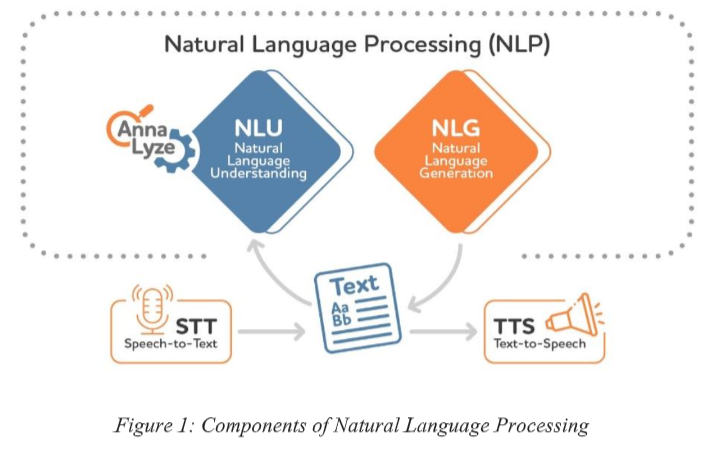
Natural Language Understanding (NLU) focuses on the extraction of information from text and thus on the acquisition of text understanding with respect to a certain aspect. Syntax (grammatical structure) and semantics (meaning of words) play an important role. Examples are
- grammatical analysis (e.g. part-of-speech (POS) tagging),
- ecognition of people, places or other keywords in texts (e.g. Named Entity
- Recognition (NER)),
- sentiment and opinion analysis (sentiment analysis), and
- classification of text into predefined categories. Natural Language Generation (NLG) focuses on the generation of natural language and is used, among other things, for the automated creation, summarization or translation of texts. Since NLU and NLG work exclusively with written language, a component for speech recognition (Speech-to-Text, STT for short) and speech synthesis (Text-to-Speech, TTS for short) is often required, which then act as an interface between the NLP system and the real world. For the “OK Google” example, this means that the query is converted from spoken language to written language using STT. The query, which has been recognized by NLU, can be responded to, for example, by collecting and evaluating relevant search results. The knowledge generated in this process can mostly (depending on the type of result) be played back acoustically using NLG and TTS, or the best hits can be displayed on the terminal.
Why NLP is so challenging
NLP is considered one of the most complicated problems in computer science. Natural language in itself has no identifiable structure (often referred to as unstructured data) and is a complex system of strung together, partially interdependent characters and therefore not easy to understand from the ground up. German, English, Russian, Japanese, Arabic – each language has its own complex syntax and peculiarities. In addition, there are further
complications, since language often does not function in a linear way, but makes use of different stylistic devices, idioms and information between the lines. Recognizing sarcasm is not always possible even for a human. Ambiguities of single words have to be resolved by a context analysis, e.g. to associate the German word “Bank” with a seating accomodation or a financial institution. Mumbling, stuttering, speaking in dialect, and background noise make it
difficult for the voice assistant to evaluate the information and can lead to an incorrect response. Algorithms have to face these and several other challenges in order to meet their requirements.
The awakening of the transformers
Older systems relied on rule-based or purely statistical approaches, whereas the breakthrough only came with machine learning (especially deep learning) and the availability of large amounts of data. Machine Learning models try to infer general patterns from a set of examples (How do people use language? Which grammar rules are applied?) and apply them to decide an individual case – similar to a child learning human language. The more examples the system is provided with and the better they reflect reality or the future application scenario, the higher the hit rate for new, unknown tasks the system is supposed to solve. Currently, the most promising models or state-of-the-art results for tasks from the NLP domain are obtained with Deep Learning algorithms such as transformer models, which allow more complex modeling than conventional Machine Learning models. Deep Learning was inspired by the functioning of the human brain and employs multi-layered neural networks. The highly connected structures enable “deep learning”, which is essential especially for the complex construct of language.
Tutorial summary
After completing this tutorial session you will…
- …know how computers process human language
- …know the most common NLP-tasks and how to create value for your use-case
- …be aware about challenges and possible solutions
- …have an overview of the NLP-toolbox (models, python libraries and other resources) and how to get started
Short Bio:
Markus Steindl graduated with honors from the Diploma Program in Technical Physics in 2011 and the PhD Program in Technical Mathematics in 2015 at the Johannes Kepler University Linz. As a research associate, he has worked on algebraic research topics both at the University of Colorado Boulder at the Department of Mathematics and at the Vienna University of Technology at the Department of Computer Science. After working in software and research development at Schmachtl GmbH, he joined RISC Software GmbH as a Data Scientist in 2018. He works on
various customer and research projects in diverse industrial areas.
Sandra Wartner completed her Master’s degree in Medical Informatics with highest distinction at Hagenberg University of Applied Sciences in 2017 and works as a Data Scientist in the Logistics Informatics department on
various research projects in the fields of industry and media. Since then, she has focused on a wide variety of tasks in data analytics (especially natural language processing) as well as the use of AI solutions in practical applications.